
The media industry has been fighting the wrong battle.
Most of the legal battles, licensing agreements and industry coalitions around AI and copyright have focused on training data. The core questions have been whether companies like OpenAI were allowed to use decades of journalism to train their models, whether that use constitutes copyright infringement, and whether publishers should be compensated for content that ultimately helped power a competing system.
These are all legitimate questions but training data is a historical argument about something that already happened.
The more pressing question is about what is happening right now, every day, millions of times: AI platforms citing publications in live responses and profiting from that credibility without paying a penny for it.
Training Data and Live Citation Are Two Different Things

When the New York Times sued OpenAI, the argument centred on the use of the Times’ journalism to train the GPT models. The Axel Springer deal with OpenAI covered similar ground, licensing content for training purposes.
These agreements are about the raw material that went into building the model. Live citation is different. It is not about what the model learned but what the model says, in real time, to a real user with a real intent.
When Perplexity answers a question about the best restaurants in Paris and cites a Condé Nast Traveller review from last year, it is not drawing on training data. It is actively retrieving, summarising, and presenting that publication’s work as the basis for its answer. The editorial judgment, the reporting, the authority of the byline are all used to make Perplexity’s response trustworthy.
It is not about what the model learned. It is about what the model says, in real time, to a real user who came ready to act on the answer.
Is This Just Fair Use?
The AI platforms would argue that summarising and citing published content is no different from what Google has done for twenty years. Google’s featured snippets pull content from pages, display it without requiring a click, and nobody pays the publisher. Search engines have always operated on the premise that being indexed is itself the compensation: exposure, traffic, distribution.
That argument is weaker than it sounds in the context of AI-generated responses.
Google’s snippets send some traffic. Users who want more than the snippet click through. The publication gets a reader but AI responses, by design, aim to be the complete journey. The goal of a well-constructed AI answer is that the user does not need to go anywhere else. That is not incidental to how these platforms work, it is the product. And when the product is designed to replace the click, the old justification for unpaid citation collapses.
The other side of the fair use argument is transformation. Copyright law generally allows reproduction if the new use is transformative. If it adds meaning, context, or value rather than simply reproducing the original. An AI answer that summarises a review and uses it to recommend a hotel to a traveller is doing something the review alone could not do. That transformation argument is legally credible. But it does not resolve the commercial question, which is separate from the legal one.
The Commercial Question Nobody Is Asking
Legal debates about fair use ask: is this permitted? The commercial question is different: even if it is permitted, should the value created flow entirely to the platform?
Perplexity, ChatGPT, and Gemini are subscription products. They charge users for the quality of their answers. The quality of their answers depends, in part, on the quality of the sources they cite. A Perplexity answer that draws on the Financial Times carries more authority than one that draws on an anonymous blog. That differential authority is something the platform captures commercially, in the form of subscription revenue, and something the publication provides at no charge.
Some platforms are now selling advertising against AI-generated responses. A brand can pay to appear in an AI answer. The AI answer will still cite editorial sources to support the recommendation. The brand pays, the AI profits, but the publication that provided the credibility underpinning the whole thing gets nothing.
Even if live citation is legally permitted, that does not mean the value created should flow entirely to the platform.
What a Payment Model Could Look Like
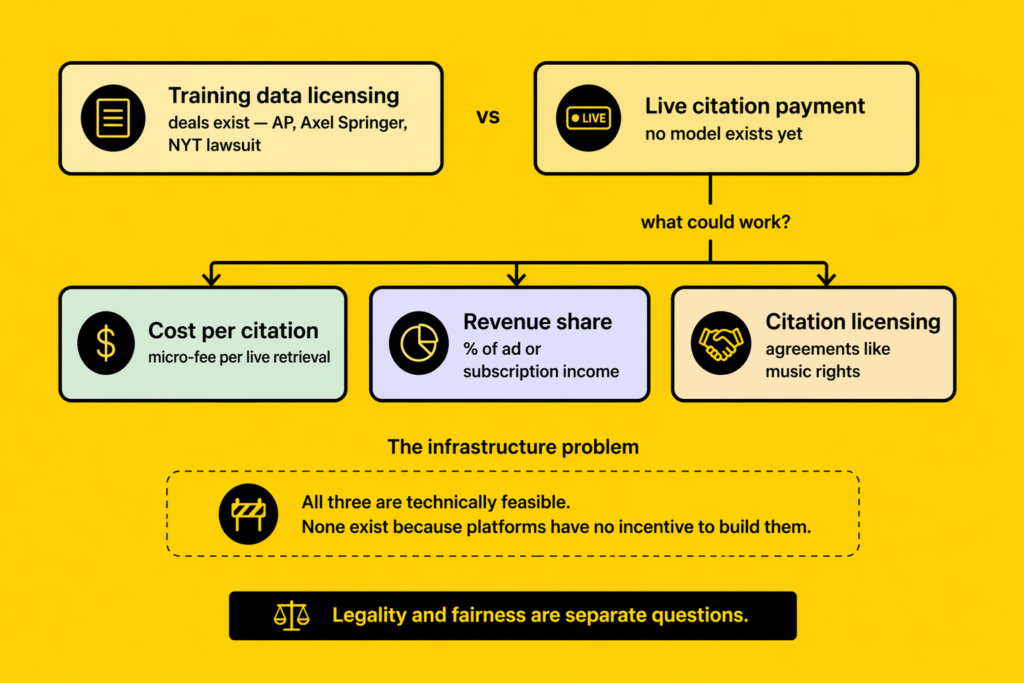
Nobody has built a citation payment model yet, but the logic of one is not complicated. Citations are measurable. AI platforms know exactly which sources they cite, how often, and in what contexts. That data already exists. The question is whether there is any political or commercial will to use it.
A cost-per-citation model would charge platforms a small fee each time they actively retrieve and present content from a publication in a live response. A revenue share model would give publications a percentage of the ad revenue or subscription revenue generated by responses that used their content. A citation licensing model would require platforms to enter agreements with major publishers before using their content in real-time retrieval, similar to the way music streaming services license catalogues.
Each of these models has complications. Scale is one of them: the volume of citations across all AI platforms is enormous, and micro-payments at that scale require infrastructure that does not currently exist. Quality assessment is another: not all citations carry the same value, and any model would need to account for the difference between a citation that drives a commercial decision and one that merely adds context.
But the complications are engineering problems, not impossibilities. The reason none of these models exist is not that they are unworkable. It is that the platforms have no incentive to build them, and the publications have not yet coordinated a response powerful enough to force the issue.
What Publications Can Do Now
Waiting for a regulatory or legal resolution is not a strategy. That process will take years and may not resolve in the media’s favour.
The more immediate question for any publication is: do you know your citation authority? Do you know how often you are being cited, on which platforms, in which categories? Do you know whether your content is structured in a way that makes citation more likely, and whether that citation is being attributed to your title or dissolved into a generic summary that mentions no source at all?
Understanding your citation position is not the same as getting paid for it. But it is the first step toward being able to make any argument about value at all. If you cannot demonstrate what you are contributing to the AI economy, you cannot negotiate for a share of it.
In the next piece in this series, we look at the brand sitting in the middle of this transaction — paying for AI recommendations while the publication that made those recommendations credible gets quietly written out of the deal.

Written by
Sara Lemos
Co-founder of Make Lemonade. Sara leads AI visibility strategy and digital intelligence, helping luxury hospitality and travel brands appear in AI-generated recommendations.
View full profilePrevious article
The Invisible Debt: AI Is Built on Media. Who Gets Paid?