
This series began with a simple observation: AI platforms are built on media content, and the media industry is not being paid for it. Over three articles, we have traced what that means in practice, from the basic attribution problem, to the legal and commercial questions around live citation, to the brands sitting in the middle of a transaction that benefits everyone except the source that made it credible.
This final piece asks the forward question: if the industry were to build a proper AI citation attribution model, what would it actually look like? The answer matters because the conversation about AI and media has been dominated by lawyers and lobbyists arguing about what happened in the past. The more commercially urgent conversation is about what AI citation attribution infrastructure needs to exist going forward, and who would benefit from building it.
The Problem Any AI Citation Attribution Model Has to Solve
Any workable AI citation attribution model has to solve a few distinct problems simultaneously.
First, it has to distinguish between citation types. A passing reference to a publication name is different from an answer that retrieves, summarises, and presents a specific article as the primary basis for a recommendation. Both are citations. Only one carries real commercial weight. A model that treats them the same will either over-compensate for trivial references or under-compensate for the citations that actually drive user behaviour.
Second, it has to handle scale. Across ChatGPT, Perplexity, Gemini, Claude, and the dozens of AI tools built on top of them, the volume of citations happening in any given day is enormous. The infrastructure for tracking, verifying, and settling micro-payments at that scale does not currently exist. This is an engineering problem, not an impossibility, but it is a significant one.
Third, it has to be something platforms have an incentive to participate in. The current situation is comfortable for the platforms. They benefit from citation authority they did not create and pay nothing for it. Any attribution model will require either regulatory pressure, coordinated publisher action, or a commercial argument compelling enough that platforms see participation as advantageous.
Three AI Citation Attribution Models That Could Work
None of these models exist yet. All of them are technically feasible.
Cost-per-citation. The most direct model. Each time an AI platform retrieves and presents content from a publication in a live response, a micro-payment is triggered. The rate would vary based on citation depth: a full article summary used as the primary source in a response would generate a higher payment than a brief reference. The infrastructure required is a real-time citation tracking layer and a payment settlement system. This is similar in principle to how ad tech works: many small transactions, cleared in near-real time across thousands of counterparties.
Revenue share on AI advertising. As AI platforms introduce advertising products, a percentage of the revenue from any response that drew on editorial content could flow back to the cited source. The precedent is music streaming: Spotify paid out over $9 billion in royalties in 2023 alone, sharing subscription revenue with rights holders based on streams. The analogy is not perfect, citations are not streams, but the underlying logic is similar. Value is generated using someone else’s intellectual property, and a portion of that value flows back to the creator.
Citation licensing agreements. Publications negotiate directly with AI platforms for the right to include their content in real-time retrieval systems, separate from and in addition to any training data agreements. The AP already has a content agreement with OpenAI. That deal covers training data; a citation licensing layer would extend it to live responses. Larger publishers could negotiate individually; smaller publications could pool into collective licensing bodies, similar to how ASCAP and PRS handle music rights.
The precedent exists in music streaming. Value is generated using someone else’s work, and a portion flows back to the creator. The infrastructure question is harder than the principle.
What AI Citation Attribution Changes for Media Buying
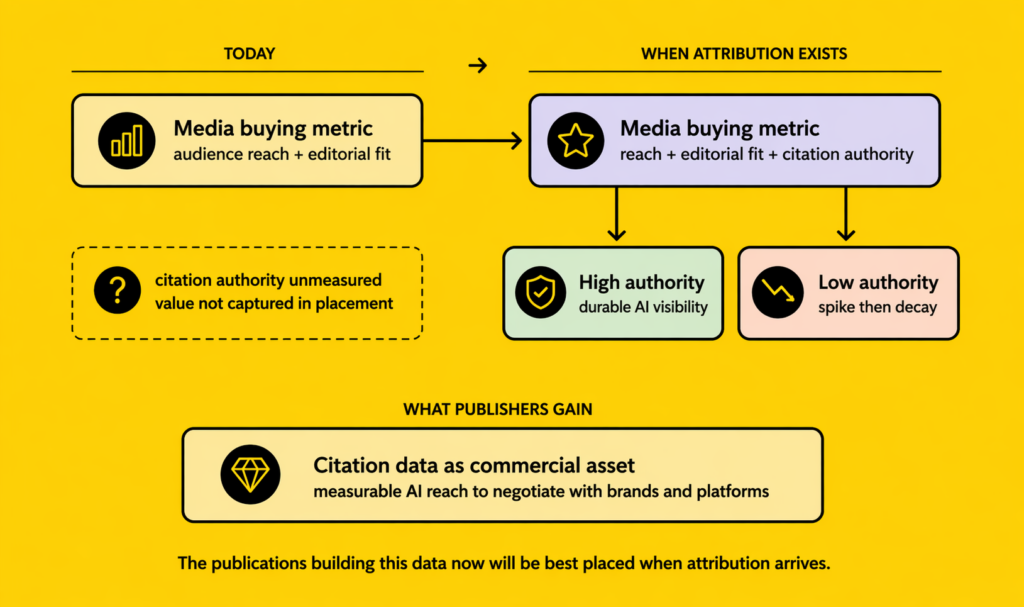
If any version of citation attribution becomes standard, it changes the logic of media buying in a meaningful way.
Currently, brands buy media based on audience reach and editorial alignment. A placement in a travel title reaches travel readers. That is the transaction. In a world where citation authority matters to AI visibility, a second metric enters the equation: how often is this title cited by AI platforms in responses relevant to my category?
A title with 200,000 readers but strong AI citation authority in luxury travel might generate more durable commercial value for a brand than a title with 2 million readers but low AI citation weight. The placement in the first title creates a trust signal that AI platforms retrieve and deploy over time. The placement in the second title has a spike and a decay.
This is not a replacement for traditional media metrics. Audience reach still matters. But citation authority is an additional dimension that brands and agencies are not currently measuring, and in the AI era it is an increasingly consequential one.
What It Changes for Publishers
For publications, a functioning attribution model would do two things. It would create a new revenue stream directly from the AI platforms that are currently extracting value from their content. And it would give publications a quantified measure of their citation authority that they could use commercially, not just to negotiate with AI platforms but to demonstrate value to brands considering media investment.
A publication that can show a brand: “we are cited by Perplexity in 40% of responses about luxury hotels in Southeast Asia” has a new and compelling story to tell. That is not just editorial credibility. It is measurable AI reach, reach that extends beyond the publication’s own audience into the AI-mediated conversations happening across millions of user queries every day.
The publications that start building this data now, before any attribution model exists, will be best placed to use it when the model arrives, and to make the commercial case for their own value in the meantime.
Where Make Lemonade Sits in This
We built Signal Noir to measure citation authority precisely because this infrastructure does not yet exist at an industry level. The publications we audit, the brands we advise, and the agencies we work with are all navigating an ecosystem where citation drives credibility and credibility drives commercial outcomes, but most of the participants do not have the data to see it clearly.
The AI citation attribution framework that the industry needs will take time to arrive. In the meantime, the brands, publications, and agencies that understand their citation position are the ones making informed decisions. Everyone else is operating on assumptions about media value that AI has quietly made obsolete.
If you want to understand your citation position, that is where this series ends and the work begins.
Previous article
The Brand in the Middle: Where the Money Goes and Where It Should